YOLOv10针对带噪声数据集的鲁棒性提升研究
真特么的是忙疯了,这段时间。OBWC带领中国队杀进RO16固然是好事,但是妈的我跟你说,呀噫씨발,OBWC作图时间就两周(虽然后来延长了大约四天但还是不大够,期间交涉还出了点问题),第一周,期末考。第二周,小学期项目,wow!累死你罢了。好在两个都以一种不是那么完美的方式,收工了吧……?哎呀算了过都过去了,OBWC面对的是#1 KR,能打得过才有鬼了。小学期这个……能过就行,算求了。
不过说到底,YOLOv10这个针对噪声的训练我觉得还是挺值得一写的,毕竟第一,思路是正确的,技术栈实现也没问题,第二,他妈的我为了训练一个模型等到半夜四点多,快天亮了终于训练成功然后跟个啥b一样对着屏幕疯狂yes打拳结果第二天起来一看卧槽精度这么低ppt还没做完蛋了,起因是不想答辩。废话不多讲,进正文。
动机?
不想答辩。
话不能说太死,倒是也是想试试这个模型的上限在哪,当时看到这个命题:“有树枝遮挡,也就是有噪声的情况下依然能够识别出无人机对象”,脑子里其实就有一个想法了。目前几乎所有的人工智能模型都高度依赖大量的数据训练,我们可以把清晰的对象称为正样本,Positive Sample,对模型起到一个正面的训练作用。但是俗话又说回来了,雅俗共赏,一个只知道听高雅音乐的人,大门不出二门不迈,注定会成为一个上流庸俗的掉书袋。模型也是一样,只看清晰的无人机图像,模型本身就成为了存在于乌托邦里面的一个东西。什么是干扰?不知道。什么是脏数据?不知道。什么是噪声?哎呀我只会识别清晰的图像,这个脏脏的(被树枝遮挡)一看就不是无人机,我不看我不看。谁会要这种模型,我问,一脚踢路边了。
扯远了。所以这个时候就需要引入困难正样本(Hard Positive Sample,我习惯称脏数据,不知道别人是不是这么叫)、负样本(Negative Sample)和困难负样本(Hard Negative Sample),让模型知道,带有噪声的数据。不能让它去“猜”,而是事先告诉它如何去做。思路很简单,但是当涉及到具体实现的时候就开始麻烦了。
环境搭建
自己查去。
具体实现
基准模型测试(v1_model)
时间、算力和成本都有限,不可能做到非常好的效果,想要尽可能的优化效果,在这么短的时间内手动标记几万张数据集肯定不可能,除非你是超人。所以去RoboFlow下载事先标注好的数据集:https://universe.roboflow.com/tracker-qjlj1/drones_new。
YOLOv8和YOLOv10的数据集是兼容的,都是image + xml Label的效果,并且会有一个data.yaml用来指示路径。所以选择YOLOv8,curl拉取到本地。这是一个相对比较庞大的数据集,两万张图片(虽然有3/4是一张图片旋转、滤净化处理以及加入一点可怜的噪点象征性的作为噪声,但是足够了)用来训练。长这样:
Wide Putin.jpg
可以看到绝大多数都是随意拍摄的无人机照片,确实也有起到一定的干扰作用,至于翻转和噪点……我的评价是有总比没有好。
先用yolov10s.pt这个相对不大不小的基准模型进行训练。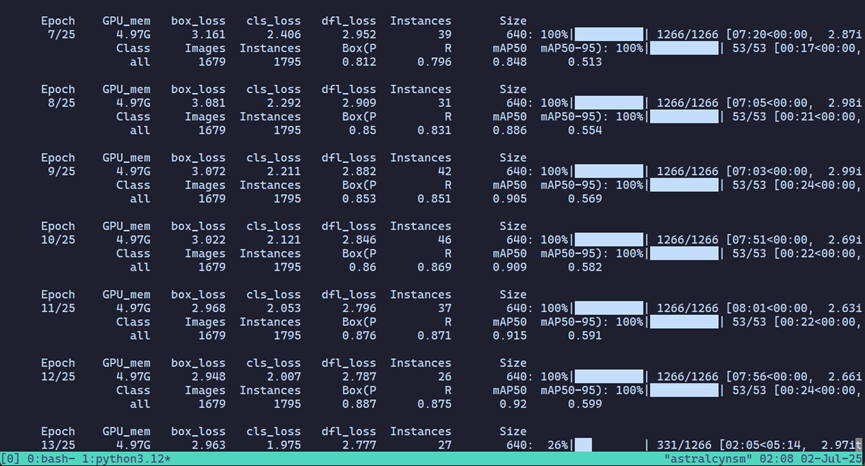
别看
其实这个是训练v2模型的截图,第一轮忘记截图了.jpg
训练完毕之后,查看结果
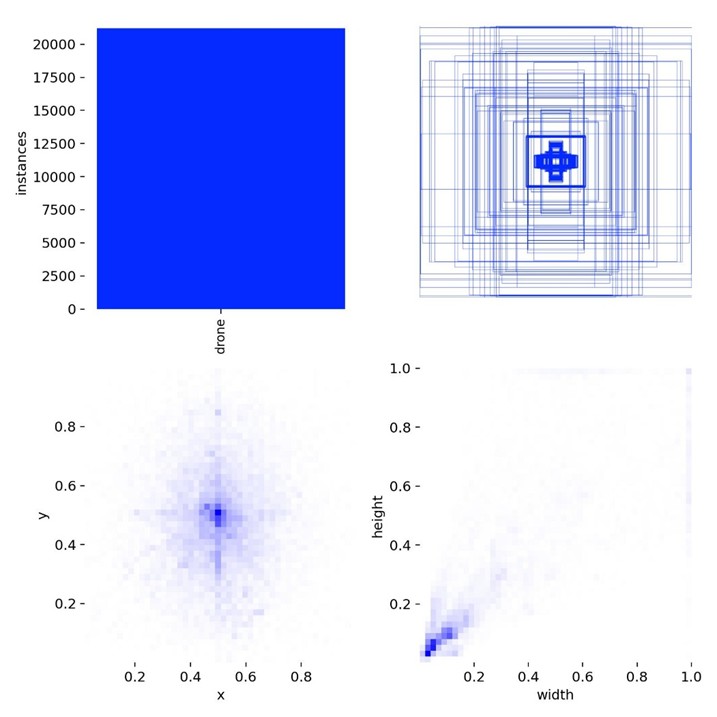


在干净的数据集上实际上训练结果是相当不错的,框选范围大致正确,置信度也相当不错,说明模型在干净的正样本上已经达到了不错的拟合效果。我们来看results.csv:
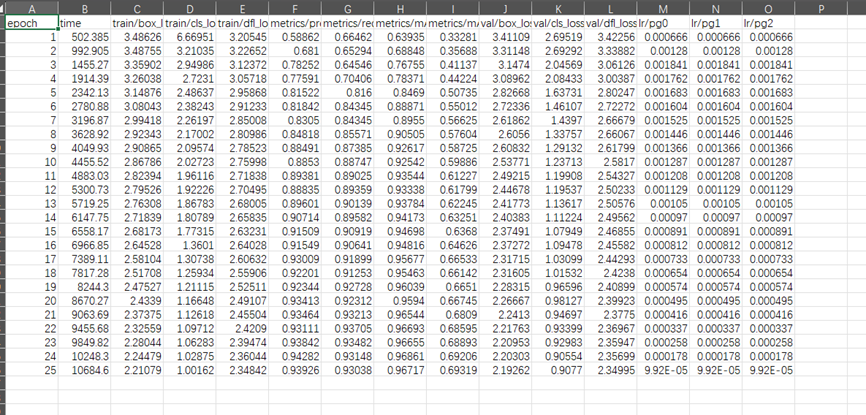
我选定的训练轮次是25轮。但是查看各个损失函数(从C到E、J到L)可以看到,epoch=25的时候虽然下降速度已经开始放缓,但是仍然有明显的下降趋势,证明epoch=25对于当前训练来说是不够的。而mAP也达到了96.717%的水平,非常接近数据集所提供的96.8%,基本可以证明数据集的质量相当不错,只是模型并没有拟合到位。
但是,即便有这样的数据支撑,现在的v1基准模型,确实就是一个上流庸俗的掉书袋: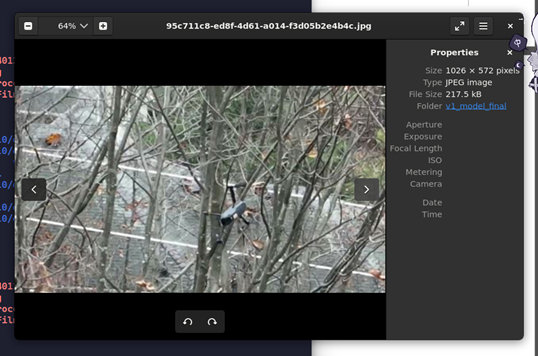
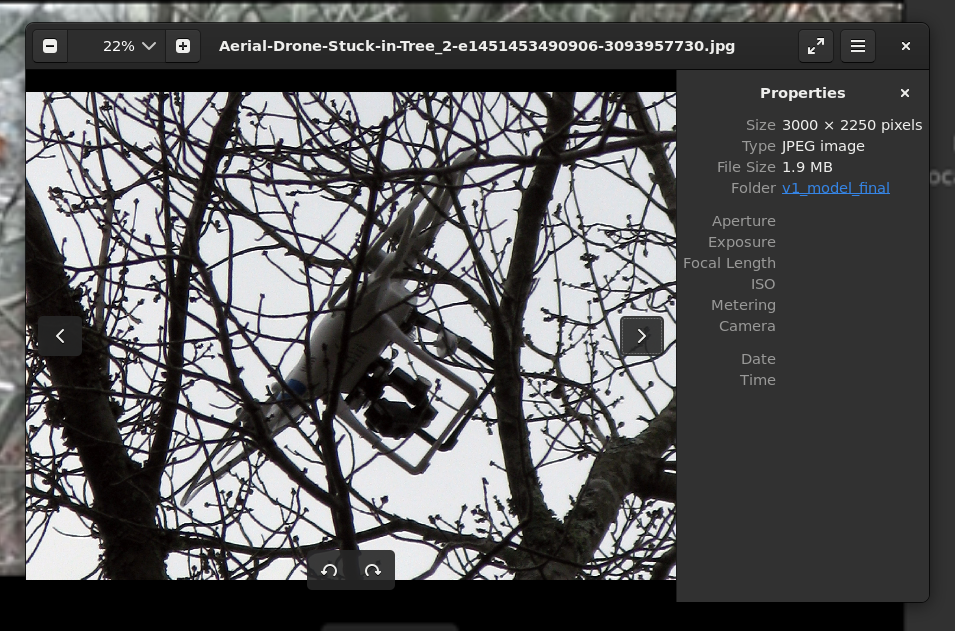
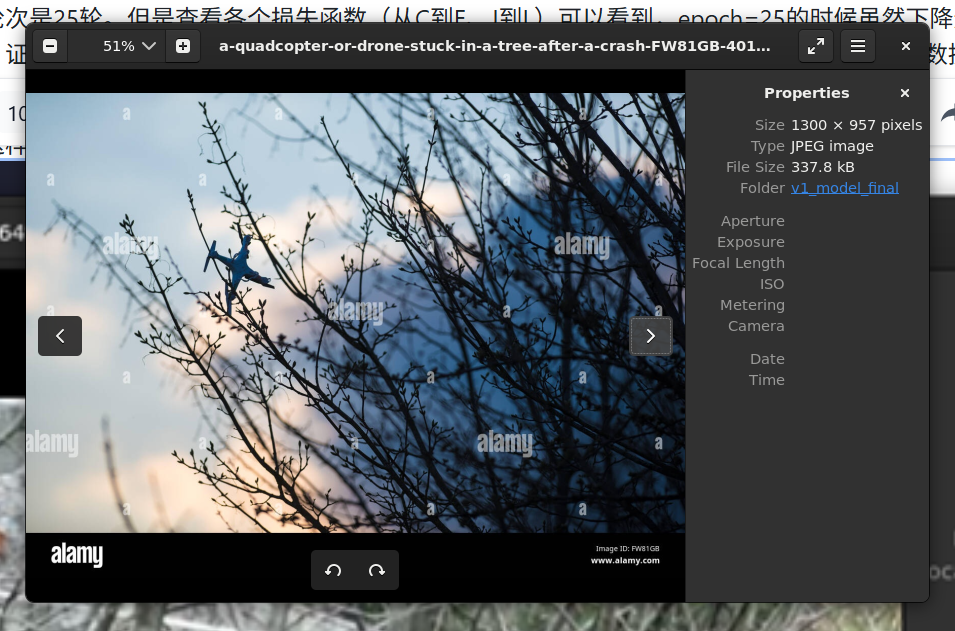
模型完全瞎了.jpg
可以看到,基准模型在这些测试数据上,人眼可以一眼就看出来、明显看出来有无人机的情况下,模型彻底瞎了。他不知道这在树枝之间层层绕绕的是一个无人机。同样:
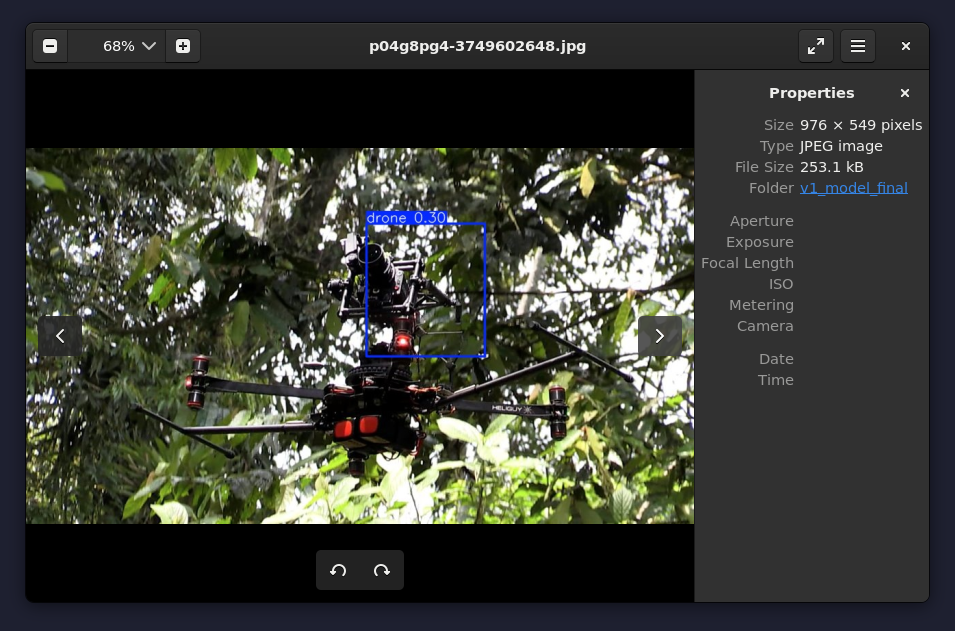
图片来源于BBC纪录片
在这种复杂场景的、非典型形状(头顶摄像机的情况下),模型的识别结果非常奇怪,不仅置信度极低,并且框选的范围也很怪异,大概率是把背景的树枝一起当做无人机的一部分了。这恰恰说明了基准模型对于实际的、复杂的、带有噪声的受干扰的场景识别效果极差,基本无法投入到实际使用当中去。所以我们进入第二部分:
基于目标感知的随机遮挡数据增强(v2_model)
Python代码如下(感谢Gemini的帮助(说的那么好听还不是借助AI的力量写了代码))
查看data.yaml可以看到只有drone一个类别,所以drone的类别标签理所当然的就是0(a_drone_id):
import os
import random
from PIL import Image
import shutil # 用于复制文件,更健壮
# --- 配置参数 (已根据你的目录结构适配) ---
# 假设'drone'的类别ID是0,请根据你的data.yaml文件确认
a_drone_id = 0
train_images_path = './train/images/'
train_labels_path = './train/labels/'
occluders_path = './occluders/'
# --- 新增配置参数 ---
num_images_to_augment_and_overwrite = 10000
# --- 后续代码无需修改 ---
if not os.path.exists(occluders_path) or not os.listdir(occluders_path):
print(f"错误: 'occluders' 文件夹不存在或为空。请下载一些PNG遮挡物图片放进去。")
exit()
occluder_files = [f for f in os.listdir(occluders_path) if f.lower().endswith('.png')]
if not occluder_files:
print(f"错误: 'occluders' 文件夹中没有找到PNG格式的遮挡物图片。")
exit()
all_eligible_images = []
for f_name in os.listdir(train_images_path):
if f_name.lower().endswith(('.png', '.jpg', '.jpeg')):
label_name = os.path.splitext(f_name)[0] + '.txt'
label_path = os.path.join(train_labels_path, label_name)
if os.path.exists(label_path):
all_eligible_images.append(f_name)
drone_containing_images = []
for image_name in all_eligible_images:
label_name = os.path.splitext(image_name)[0] + '.txt'
label_path = os.path.join(train_labels_path, label_name)
has_drone = False
try: # 添加try-except防止读取标签文件时出错
with open(label_path, 'r') as f:
for line in f.readlines():
parts = line.strip().split()
if len(parts) != 5: continue
class_id = int(parts[0])
if class_id == a_drone_id:
has_drone = True
break
except FileNotFoundError:
print(f"警告: 标签文件 {label_path} 未找到,跳过图片 {image_name}。")
continue
except Exception as e:
print(f"警告: 读取标签文件 {label_path} 时发生错误: {e},跳过图片 {image_name}。")
continue
if has_drone:
drone_containing_images.append(image_name)
random.shuffle(drone_containing_images)
images_to_process = drone_containing_images[:min(num_images_to_augment_and_overwrite, len(drone_containing_images))]
print(f"找到 {len(all_eligible_images)} 张原始训练图片。")
print(f"其中 {len(drone_containing_images)} 张包含无人机。")
print(f"将从包含无人机的图片中随机选择 {len(images_to_process)} 张进行遮挡增强并覆盖原图...")
print(f"找到 {len(occluder_files)} 个遮挡物。")
print(f"将为类别ID为 {a_drone_id} 的目标添加遮挡...")
processed_successfully_count = 0
failed_to_process_count = 0
for image_name in images_to_process:
image_path = os.path.join(train_images_path, image_name)
label_name = os.path.splitext(image_name)[0] + '.txt'
label_path = os.path.join(train_labels_path, label_name)
if not os.path.exists(image_path) or not os.path.exists(label_path):
print(f"警告: 跳过 {image_name},因为图片或标签文件不存在。")
failed_to_process_count += 1
continue
try:
main_image = Image.open(image_path).convert("RGBA")
except Exception as e:
print(f"错误: 无法打开图片 {image_name}。原因: {e}。跳过此文件。")
failed_to_process_count += 1
continue
img_w, img_h = main_image.size
# 读取所有标签行
try:
with open(label_path, 'r') as f:
lines = f.readlines()
except Exception as e:
print(f"错误: 无法读取标签文件 {label_name}。原因: {e}。跳过图片 {image_name}。")
failed_to_process_count += 1
continue
# 临时变量,记录这张图是否真的被添加了遮挡(例如,如果它包含无人机)
image_actually_modified = False
# 对图片中的每个无人机目标添加遮挡
for line in lines:
parts = line.strip().split()
if len(parts) != 5: continue
class_id, x_c, y_c, w, h = map(float, parts)
if int(class_id) != a_drone_id:
continue # 只为无人机添加遮挡
# 计算Bounding Box的实际像素坐标
box_w = w * img_w
box_h = h * img_h
x_min = int((x_c * img_w) - (box_w / 2))
y_min = int((y_c * img_h) - (box_h / 2))
# 随机选择遮挡物
occluder_name = random.choice(occluder_files)
occluder = Image.open(os.path.join(occluders_path, occluder_name)).convert("RGBA")
# 随机调整遮挡物大小 (比如是目标框宽度的30%到120%)
scale = random.uniform(0.3, 1.2)
new_occ_w = int(box_w * scale)
if new_occ_w == 0: continue
new_occ_h = int(new_occ_w * (occluder.height / occluder.width))
if new_occ_h == 0: continue
occluder = occluder.resize((new_occ_w, new_occ_h), Image.LANCZOS)
# 随机旋转
angle = random.randint(-90, 90)
occluder = occluder.rotate(angle, expand=True, fillcolor=(0,0,0,0))
# 随机放置在目标框附近,并确保范围有效
rand_x_start = -int(occluder.width / 4)
rand_x_end = int(box_w - 3 * occluder.width / 4)
if rand_x_end < rand_x_start:
rand_x_end = rand_x_start
paste_x = x_min + random.randint(rand_x_start, rand_x_end)
rand_y_start = -int(occluder.height / 4)
rand_y_end = int(box_h - 3 * occluder.height / 4)
if rand_y_end < rand_y_start:
rand_y_end = rand_y_start
paste_y = y_min + random.randint(rand_y_start, rand_y_end)
# 粘贴遮挡物
main_image.paste(occluder, (paste_x, paste_y), occluder)
image_actually_modified = True # 标记这张图被修改了
# --- 关键改变:覆盖原始文件 ---
if image_actually_modified: # 只有当图片实际被添加了遮挡时才保存
try:
# 将处理后的图片保存回原始路径,覆盖原文件
main_image.convert("RGB").save(image_path)
processed_successfully_count += 1
except Exception as e:
print(f"错误: 无法保存图片 {image_name}。原因: {e}。此图片处理失败。")
failed_to_process_count += 1
else:
# 如果图片被选中但没有任何无人机目标,或者所有目标都被跳过了,这里也会被计数
# 但为了保证num_images_to_augment_and_overwrite的准确性,这里不增加任何计数
pass
print(f"\n处理完成!")
print(f"成功将 {processed_successfully_count} 张图片替换为带遮挡版本。")
print(f"因错误跳过的图片数量: {failed_to_process_count}")
print(f"训练集总图片数量仍为 {len(all_eligible_images)} 张 (其中 {processed_successfully_count} 张已替换为增强版)。")小插曲:cat add_occlusion.py | clip.exe对中文的编码支持比较搞笑,所以用了powershell.exe -Command "Get-Content -Path 'add_occlusion.py' -Encoding utf8 | Set-Clipboard"。powershell是微软的亲儿子,可以很好的解决编码问题
大概解释一下代码就是,先识别图中有没有无人机,有的话就从../occlusion里面随机挑选一张透明底的.png进行旋转、缩放之后遮挡无人机,用这种手动遮挡的方式,即便是人工处理也能让模型学到被树枝遮挡的无人机是什么样的。很笨,没有什么奇特的方法,但是管用。
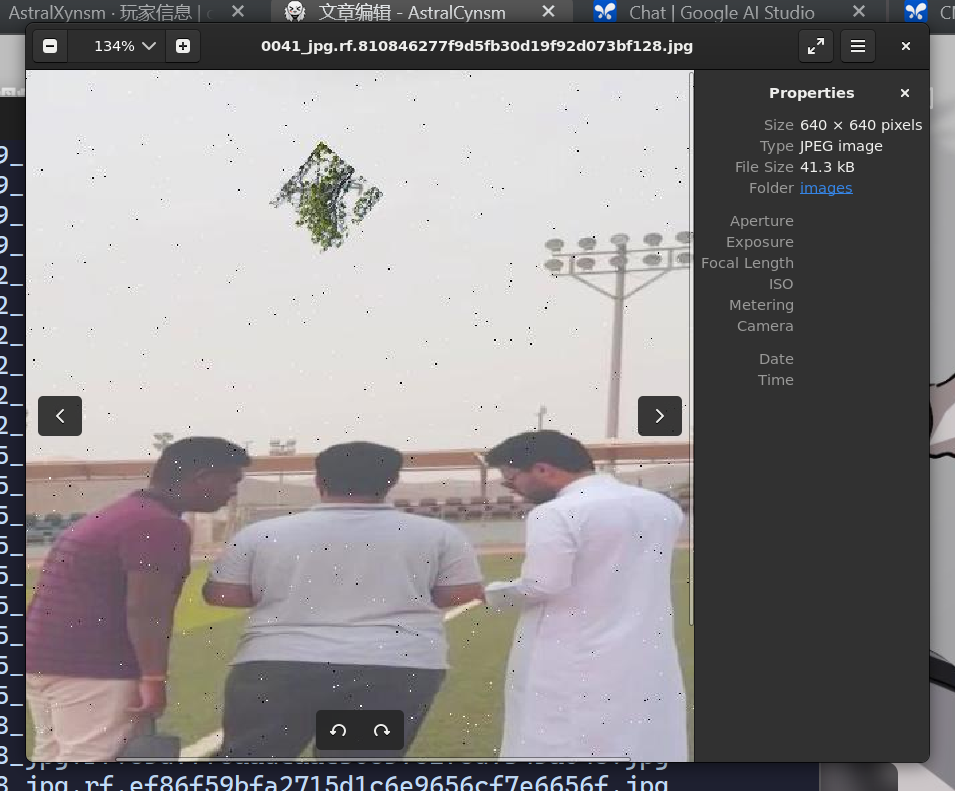
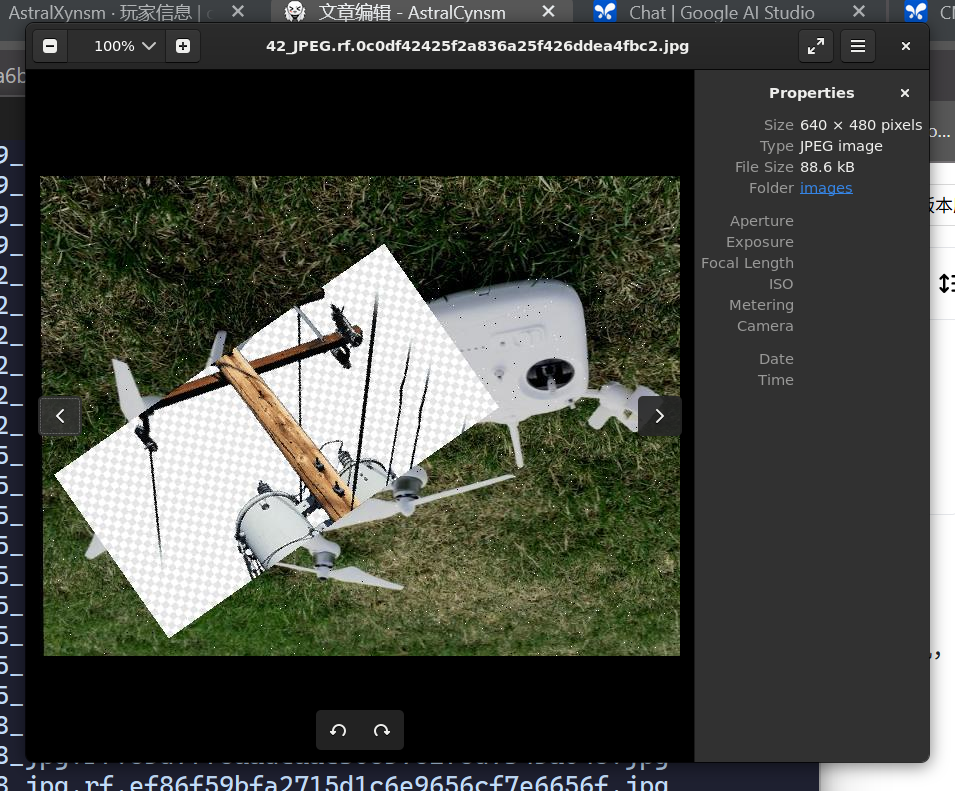
假透明底气死我也
不是很好看,但是这反正不是艺术鉴赏要啥自行车,能让模型知道是什么已经谢天谢地了。
这样从原始数据集(两万张)当中随机选取一万张进行如图所示的处理,然后训练。
训练完毕之后,重新进行预测:
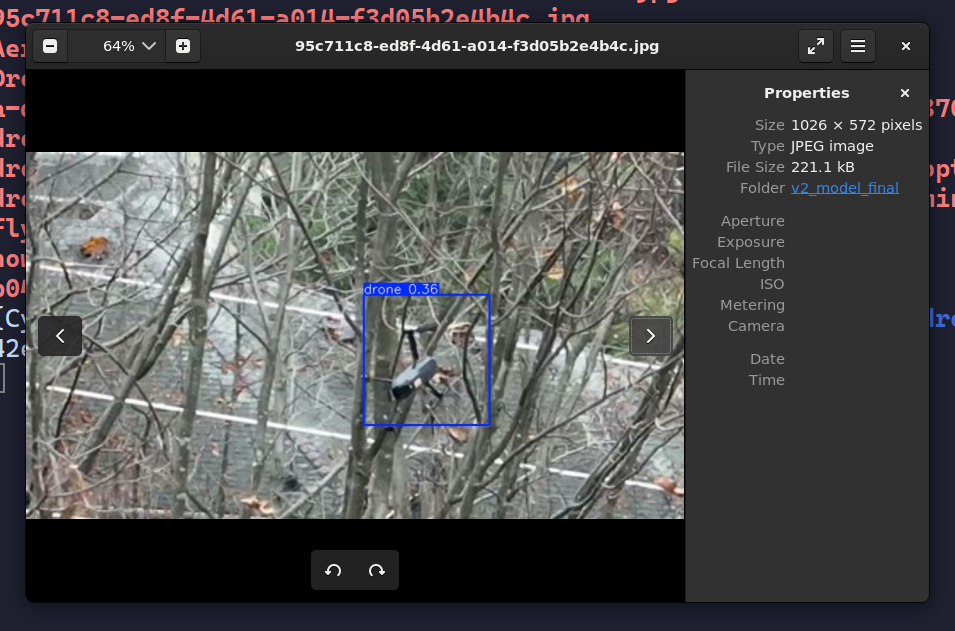
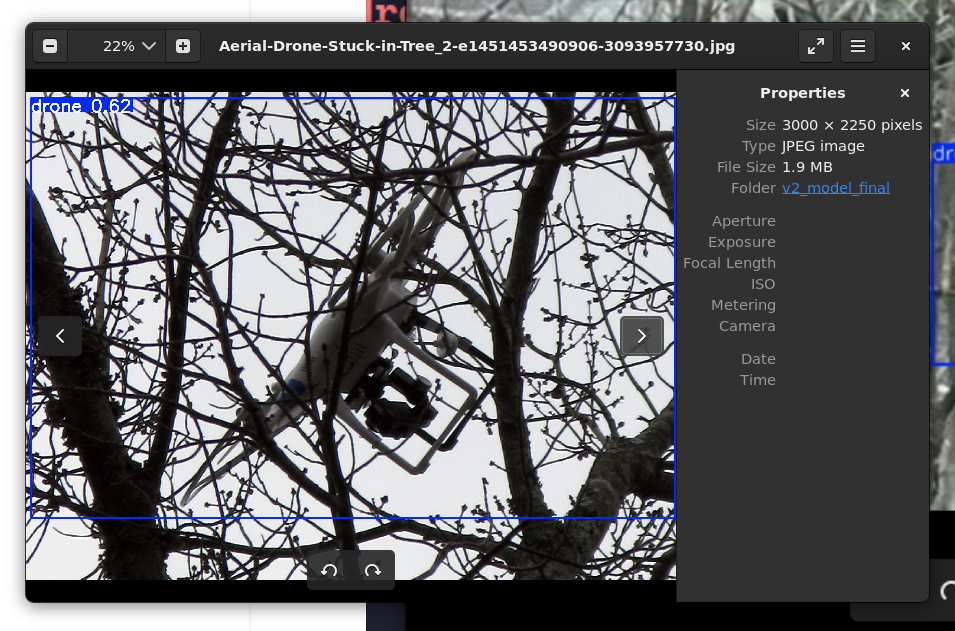
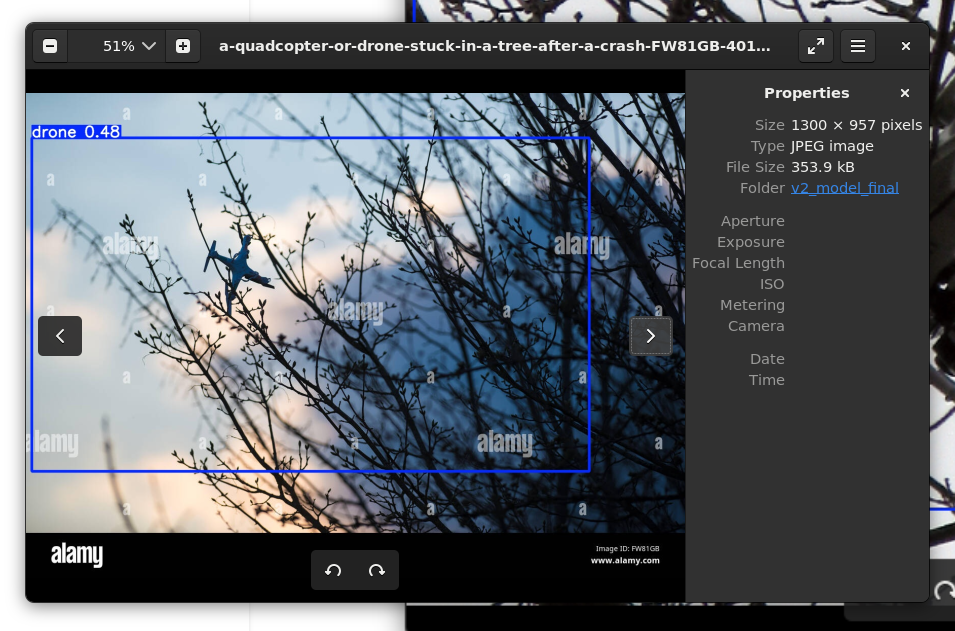
虽然可以看到,置信度仍然处于一个相对低的水平(0.36,0.48),并且框选在一些图片上显得过大,但是它出现了。从0到1的突破
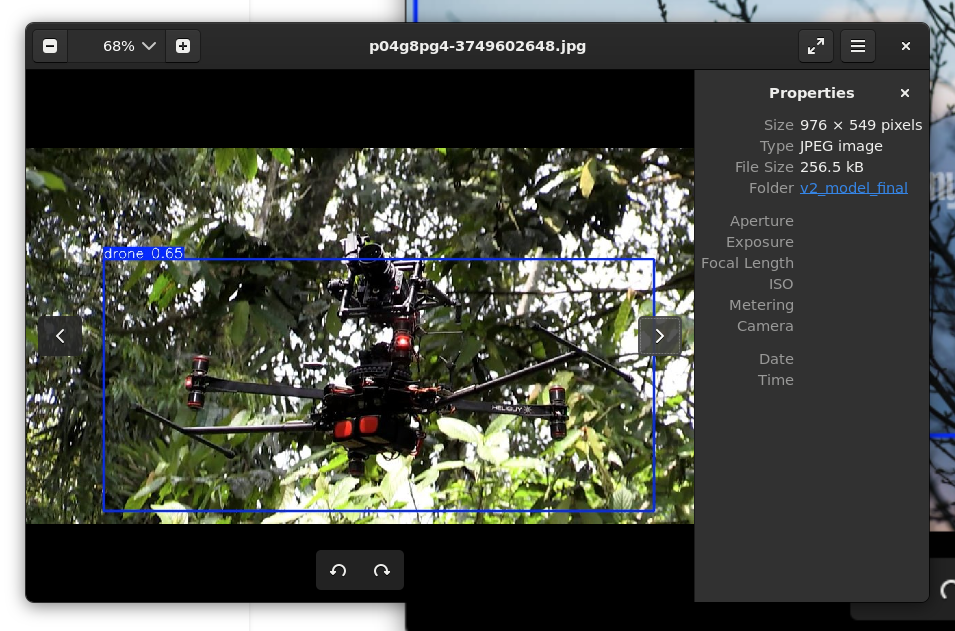
这张更是重量级,置信度直接翻倍,而且整个带摄像头的无人机全部识别出来了。
为什么?
因为模型知道被树枝遮挡、干扰的无人机长啥样了,意思就是,它被带有噪声的数据训练过后,用一个通俗的说法就是,开始理解无人机是什么样了。
不过,模型在清晰的无人机图片上面的置信度反而下降了,并且出现了奇怪的框选问题:
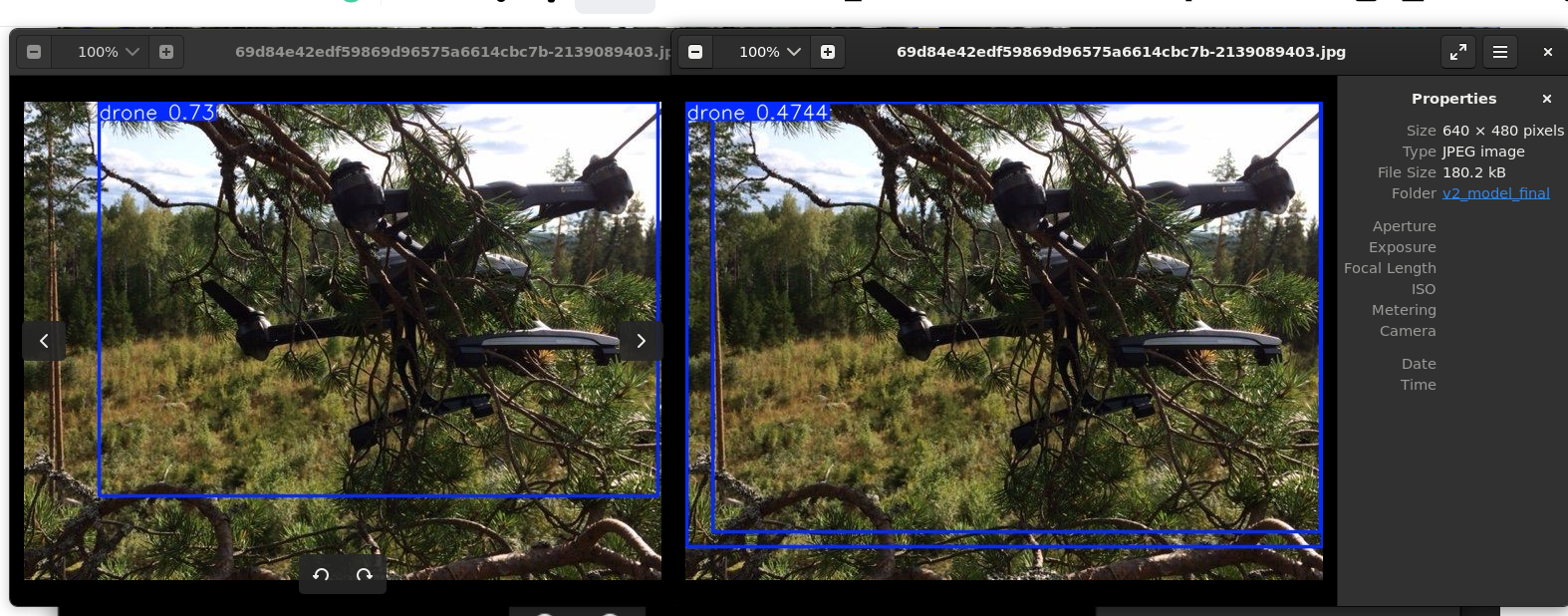
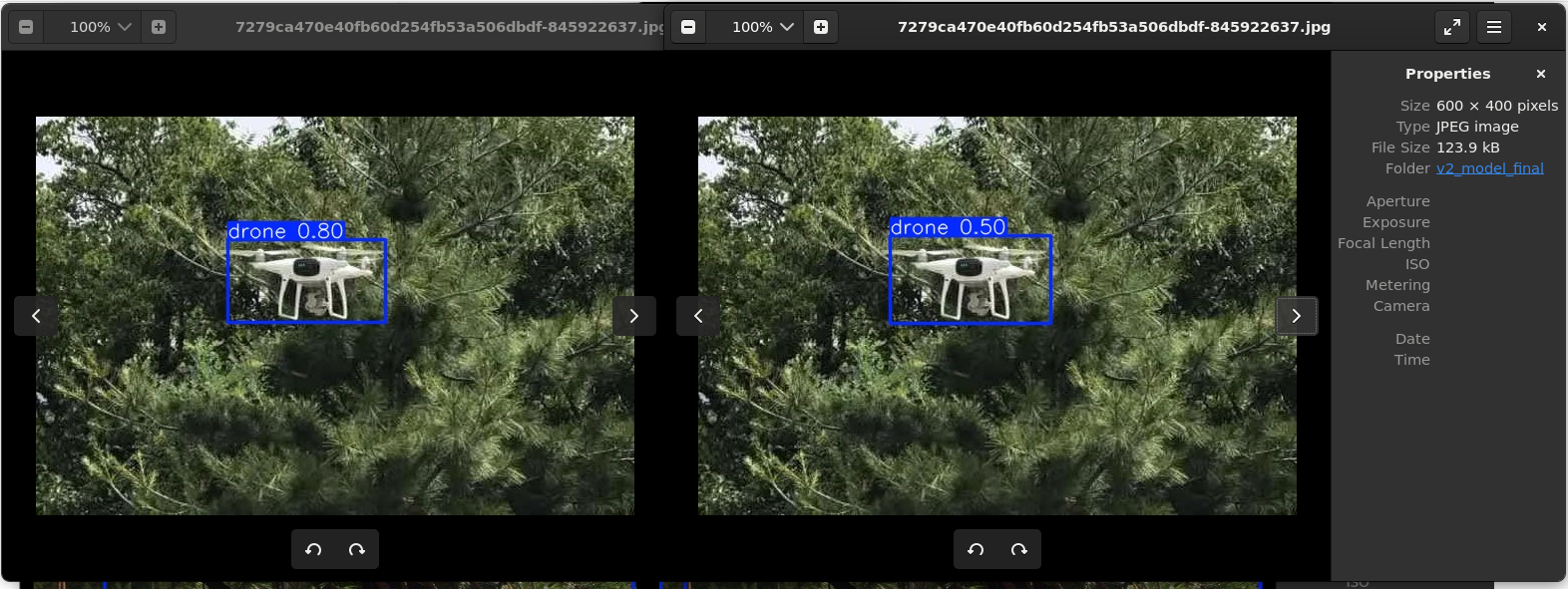
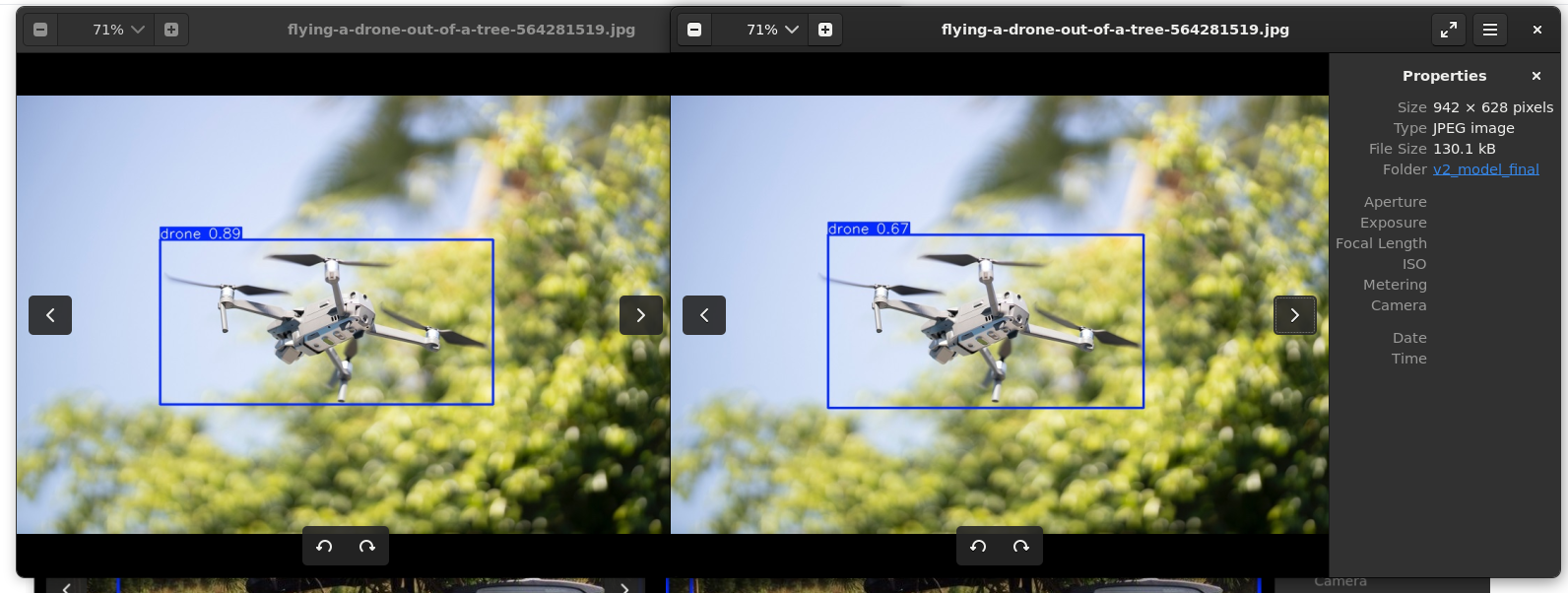
这反而是在预料之中的。为什么?
第一:v1模型原先的数据集是两万张清晰的无人机图像,没有噪声干扰的无人机图像。两万张全部用来训练清晰的无人机,那么置信度自然高。而v2模型是:一万张原始的清晰无人机图像,一万张被遮挡的带有噪声无人机图像,加起来两万张。虽然总体的数据量不变,但是对于“清晰的无人机”这一个数据类别来说,数据量减半了,自然,置信度会有所下降
第二:两种数据类型的训练并不是互相独立的,它们可以被视作为在一个Shell内的互相影响。这种情况下,困难正样本自然会影响到正样本的训练,这种情况下鲁棒性的提升是以精度的暂时下降为代价的。
我们来看v2模型的results.csv
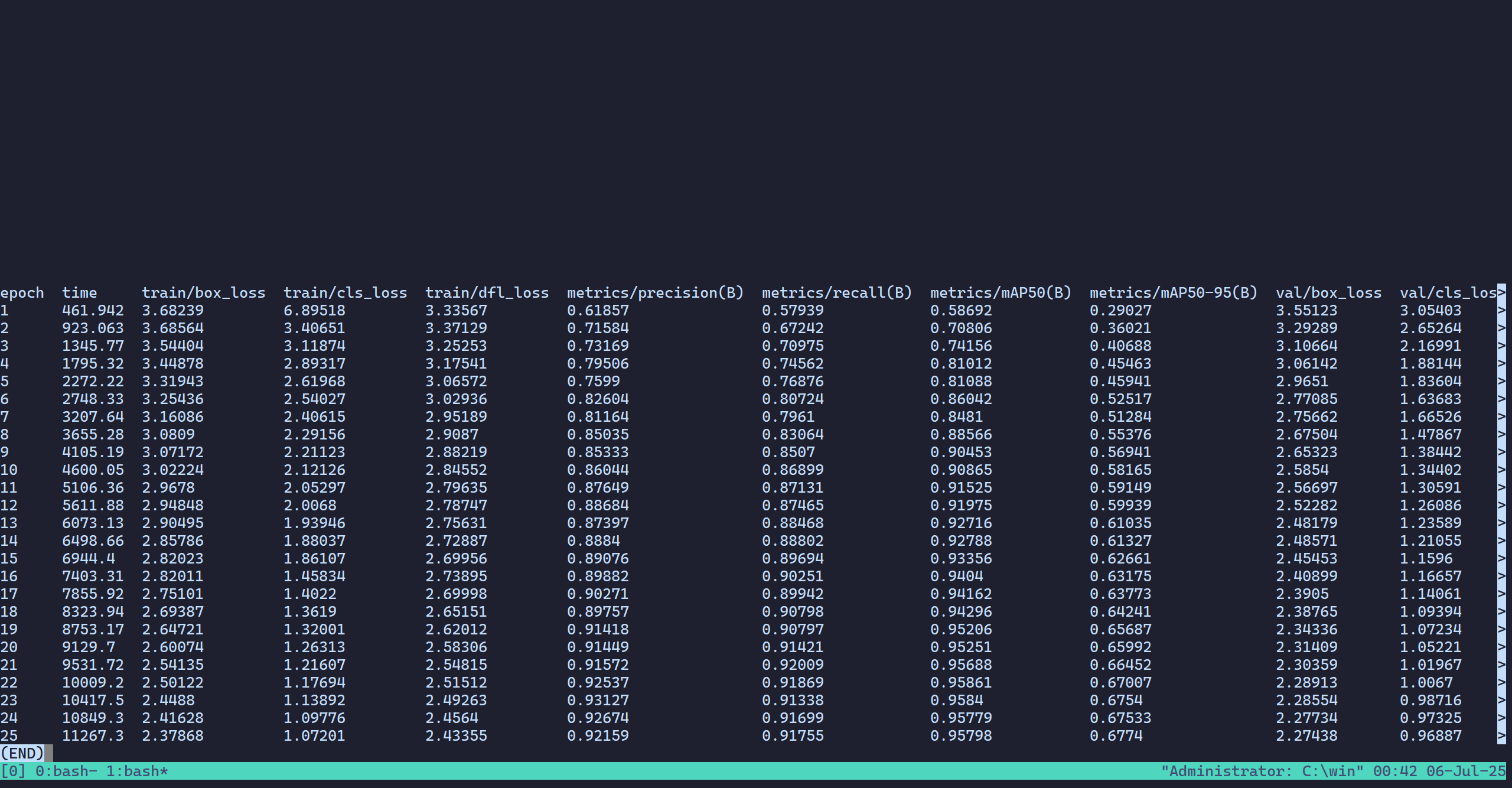
可以看到,epoch=25和v1一样是不够的。但是,我们看mAP,0.95798,也就是95.798%,损失非常小,仍然非常接近理论值的96.8%,而且相比v1的96.771%值只下降了1%左右,说明这个方法对于模型本身的性能并没有太大的影响,间接证明这个方法实际上是有效的。
后续怎么办?
目前的训练精度仍然不高。当然传统的暴力方法就是加大数据量和训练轮次(因为可以看到现在还没有完美拟合),到几万甚至几十万,现在的两万我觉得应该还是不够的。而且我实际上没有加入(或者说极少)加入负样本(完全不包含无人机的数据)和困难负样本(带有不是无人机但是很像无人机的对象的数据,比如风筝)。但是一昧增加数据量和Epoch的暴力方法实际上对于我的个人笔记本来说,时间成本实在是有些不现实,而阿里云……我祝他好运。有几个另辟蹊径的巧妙方法可以破局。
1. Focal Loss
标准的损失函数对所有样本一视同仁。而我们现在的问题是,在那些极端困难的遮挡样本上,模型学得不够好,不够自信。我们可以通过修改损失函数,让模型在训练时,把更多的“注意力”和“惩罚”放在这些难样本上。
焦点损失最初是为解决正负样本不平衡问题设计的,但其核心思想是降低简单样本的权重,让模型专注于学习困难样本。它的公式里有一个调制因子 (1-p)^{\gamma}。完整的Focal Loss函数长这样:L_{\text{FL}} = \begin{cases} -\alpha (1-p)^\gamma \log(p) & \text{if } y=1 \\ -(1-\alpha) p^\gamma \log(1-p) & \text{if } y=0 \end{cases},y = 1是对正样本的处理, y = 0 是对负样本的处理概率,p是模型对正确类别的预测概率,γ是超参数。当一个样本很容易被正确分类时(p很大),(1-p)^{\gamma}就很小,这个样本的损失权重就被降低了。反之,难样本的权重就相对提高了。
YOLOv10的损失函数已经是CIoU Loss + 分类和置信度损失的组合。其中分类损失部分,很多实现都默认使用了Focal Loss。可以手动调整Focal Loss的 gamma (γ) 参数,比如增大 gamma值。 增大gamma会让模型更加“歧视”那些它已经能很好识别的简单样本(比如干净、无遮挡的无人机),而把几乎全部的“精力”都投入到去“攻克”那些它搞不懂的、置信度低的困难样本(比如那些被严重遮挡的无人机)。
2. “恶意”遮挡
或者,我们现在的遮挡是随机放在无人机BBox里的。但无人机上哪些部分最重要?可能是螺旋桨、机身中央的logo或相机、机臂的连接处。如果我们的遮挡增强,能更“恶意”地优先遮挡这些关键区域,模型为了识别,就必须学会从非关键区域(比如机臂末端、起落架)来反推整个物体的存在。但这实现起来比较困难,只是作为一种理想化构想。
3. 老师模型
或者还可以先用增强数据集训练一个“老师模型”(就是现在的V2)。然后,重新初始化一个新的、结构一样的“学生模型”,用原始的、干净的数据集去训练它。但在训练学生模型时,它的损失函数不仅要拟合真实标签,还要去拟合“老师模型”在这些干净图片上给出的预测结果。老师模型因为见过遮挡数据,它在看待干净图片时,它的预测概率分布中已经蕴含了关于“哪些特征更鲁棒、更重要”的知识。学生模型通过学习老师的“思考过程”,即使没见过遮挡数据,也能学到这种鲁棒性。
这样做的好处是最终得到的模型是在干净数据上训练的,可能在干净样本上的表现会更好,同时又从老师那里继承了鲁棒性。但是流程复杂,需要跑两次完整的训练,算力消耗大。对于目前的情况,可能不是首选。
不过核心思路仍然都是一样的:通过让模型学习大量的负样本来让它逐步学习极端情况下的对象识别。
日后有机会可以试试,但是现在还是先不折磨我的4060Laptop了.jpg,8G显存被占满了。